
Benchmarking Perl
Author’s note: This article originally appeared in The Perl Journal 11. I then re-published it in The Perl Review with some updates..
Perl’s motto is “There Is More Than One Way To Do It”. Some ways are easier to read, some are faster, and some are just plain incomprehensible. Eventually, I want to know how long it takes for my Perl code to execute, and I can use the Benchmark module to find out. The Benchmark module comes with the standard Perl distribution and is written completely in Perl, so you should be able to use it right away.
Trouble with time()
The module formerly known as “builtin” is now List::Util, and the run times on the original test machine seem quite slow compared to my Powerbook. I updated the output and some of the run times for modern technology, except where noted.
Before I start with the Benchmark module, let’s think about what I must do to time an event. I need to know when the event started and when the event ended. If I know those I can determine the difference between them which I call the duration of the event. There is actually quite a bit to consider.
If I wanted to time one of my scripts, I could look at my watch when the script started, and again when it finished. If my scripts takes more than several seconds I actually might be able to do that. I do not need to rely on my watch, though, since Perl already provides a way to do this with the built-in time function which returns the system time. In this script, I record the system time twice and take the difference of the two:
my $start_time = time;
# My code here
my $end_time = time;
my $difference = $end_time - $start_time;
print "My code took ($difference) seconds\n";Since time returns seconds, this method can only record times and differences with a resolution of seconds, which might be too coarse a granularity for the really fast code that I have written. Also, remember that my script is not the only process running. The CPU does other things before it finishes my script, so the stopwatch approach does not tell me how long the CPU actually spent on my script. When the CPU is more loaded, the time to execute might even be longer, or shorter when less loaded.
Better resolution with times()
The built-in times function returns a list of the user time, system time, children’s user time, and children’s system time with a finer granularity than time (it relies on time(2)—see your system’s documentation for details), and only records the time the spent on my process. I can use the same technique that I used earlier:
my @start_time = times;
# My code here
my @end_time = times;
my @differences = map { $end_time[$_] - $start_time[$_] } (0..$#start_time);
my $difference = join ', ', @differences;
print "My code took ($difference) seconds\n";But computers are pretty fast and that code might run a lot faster than the smallest time that I can measure, even with times. To get around this I can run my code several times and measure the time it takes to run it several times then take the average. This makes the situation much more complicated. Not only I would need to make a loop to run the code several times while timing it, but I would need to figure out how the addition of the loop affected the time. You won’t have to worry about any of this if you use the Benchmark module.
The Benchmark module
Now I want to rewrite my previous examples using the Benchmark module. In code listing \ref{object}, I construct a Benchmark object to record the time. The constructor creates a list of the times returned by time and times, although I do not need to worry about that since I just want to use the abstract interface.
use Benchmark;
my $start_time = new Benchmark;
# my really slow code here
my @array = (1 .. 1_000_000);
foreach my $element ( @array ) { $_ += $element }
my $end_time = new Benchmark;
my $difference = timediff($end_time, $start_time);
print "It took ", timestr($difference), "\n";I also need a way to determine the time difference, which I can do with Benchmark’s timediff() function which returns another Benchmark object. When I want to see the times that I have measured, I use Benchmark’s timestr() method which turns the information into a human-readable string.
This function provides several ways to print the time by using additional parameters which the module’s documentation explains. The code in code listing \ref{object} produces output listing \ref{object}:
It took 16 wallclock secs ( 3.83 usr + 0.00 sys = 3.83 CPU)The first number, 16 secs, is the real time it took to execute, which should be the same as if I watched the clock on the wall. The module takes this directly from time. The next numbers are the values from times giving the user and system times, which, when summed, give the total CPU time.
I can also measure the time it takes to do several iterations of the code by using the timeit() method, which takes either a code reference or a string to eval. The function returns a Benchmark object that I can examine as before. Code listing \ref{timeit-string} shows an example with a string representation of the code.
#!/usr/bin/perl
use Benchmark;
my $iterations = 1_000;
my $code = 'foreach my $element ( 1 .. 1_000 ) { $_ += $element }';
my $time = timeit($iterations, $code);
print "It took ", timestr($time), "\n";It took 2 wallclock secs ( 1.71 usr + 0.00 sys = 1.71 CPU) @ 584.80/s (n=1000)I could do the same thing with a code reference as I show in code listing \ref{timeit-code}.
#!/usr/bin/perl
use Benchmark;
my $iterations = 1_000;
my $code = sub { foreach my $element ( 1 .. 1_000 ) { $_ += $element } };
my $time = timeit($iterations, $code);
print "It took ", timestr($time), "\n";Caution: Don’t compare benchmarks of code references and strings! Use the same for each technique that you compare since there is extra overhead with the eval needed to benchmark the code reference. This is true for timeit() and any of the Benchmark functions I demonstrate.
As I mentioned before, running a snippet of code several times might have additional overhead unassociated with the actual bits of code that I care about—the looping constructs of the benchmark, for instance. One of the advantages of the Benchmark module is that timeit() will run an empty string for the same number of iterations and subtract that time from the time to run your code. This should take care of any extra overhead introduced by the benchmarking code. The Benchmark module several functions that let you have a finer control over this feature and the module documents each one.
The function timethis() is similar to timeit(), but has optional parameters for TITLE and STYLE. The TITLE parameter allows you to give your snippet a name and STYLE affects the format of the output. The results are automatically printed to STDOUT although timethis() still returns a Benchmark object. Internally, timethis() uses timeit(). Code listing \ref{timethis-code} does the same thing as code listing \ref{timeit-code} but saves a couple of lines of code. It produces the same output, although the TITLE precedes it.
#!/usr/bin/perl
use Benchmark;
my $iterations = 1_000;
my $code = sub { foreach my $element ( 1 .. 1_000 ) { $_ += $element } };
timethis($iterations, $code, 'Foreach');Foreach: 2 wallclock secs ( 1.65 usr + 0.00 sys = 1.65 CPU) @ 606.06/s (n=1000)Example: some sums
Now that I know how long it took to run my bit of code, I am curious if I can make the time shorter. Can I come up with another way to do the same task, and, if I can, how does its time compare to other ways? Using the Benchmark module, I can use timeit() for each bit of code, but Benchmark anticipates this curiosity and provides me a function to compare several snippets of code.
The timethese() function is a wrapper around timethis(). The hash \%Snippets contains snippet names as keys and either code references or strings as values. The function returns a list of Benchmark objects for each snippet.
my @benchmarks = timethese($iterations, \%Snippets);As with anything else that deals with hashes, Benchmark uses an apparently random order timethese() to go through the snippets, so I have to keep track of which order timethis() reports the results. If I wanted to do further programmatic calculations with the times, I could store the list returned by timethese(), but for now I will simply rely on the information printed from timethis(). But first, I need something to compare.
To demonstrate timethese(), I want to compare five methods of summing an array of numbers. I give each snippet a name based on my impression of it. The Idiomatic method is the standard use of foreach. The Evil use of map in a void context seems like it might be clever, but how fast is it? The Iterator technique uses the sum() function from List::Util, which uses XS to connect the code written in C to my Perl program. I think Iterator to be competitive, so I came up with two more techniques, Curious and Silly, to spread out the field. Code listing \ref{timethese} shows these techniques as the values in \%Snippets.
#!/usr/bin/perl
use Benchmark qw(timethese);
use List::Util qw(sum);
my $Iterations = 100_000;
@array = ( 1 .. 10 );
my \%Snippets = (
Idiomatic => 'foreach ( @array ) { $sum += $_ }',
Evil => 'map { $sum += $_ } @array;',
Iterator => '$sum = sum @array;',
Curious => '$sum=0; grep { /^(\d+)$/ and $sum += $1 } @array',
Silly => q|$sum=0; $_ = join 'just another perl journal', @array;
while( m/(\d+)/g ) { $sum += $1 }|
);
timethese($Iterations, \%Snippets);On my Powerbook G3 running Mac OS 10.1.2 with perl5.6.1, I get the following output.
Benchmark: timing 100_000 iterations of Curious, Evil, Idiomatic, Iterator, Silly...
Curious: 20 wallclock secs (12.84 usr + 0.00 sys = 12.84 CPU) @ 7788.16/s (n=100000)
Evil: 6 wallclock secs ( 3.87 usr + 0.00 sys = 3.87 CPU) @ 25839.79/s (n=100000)
Idiomatic: 1 wallclock secs ( 1.01 usr + 0.00 sys = 1.01 CPU) @ 99009.90/s (n=100000)
Iterator: 1 wallclock secs ( 0.25 usr + 0.00 sys = 0.25 CPU) @ 400000.00/s (n=100000)
(warning: too few iterations for a reliable count)
Silly: 15 wallclock secs ( 9.52 usr + 0.00 sys = 9.52 CPU) @ 10504.20/s (n=100000)As I see, the sum() function from List::Util is very fast. In fact, it was so fast that for 10,000 iterations the Benchmark module could not measure a reliable time. The Idiomatic method is slightly faster than the clever use of map, but both are significantly slower than sum(), and the other methods, which I never expected to be fast, are indeed quite slow.
This comparison does not satisfy me though. What happens as the size of the array and the number of iterations changes? I ran several combinations of array size and iterations for each of the methods using a Sparc20 running Solaris 2.6 with perl5.004. Since I don’t really care about the Curious and Silly methods, I only report the results for the Idiomatic, Evil, and Iterator methods if. I ran each with arrays of sizes from 10 to 10,000 elements and iterations from 1,000 to 1,000,000 times. The longest time took about 86,000 CPU seconds. Do not try this without telling the system administrator what you are doing, especially if you named your script test—it is not nice to get email nastygrams from an administrator who thinks you have a script running amok when it is really doing exactly what you want it to do. Not that this happened to me and you can’t prove it anyway.
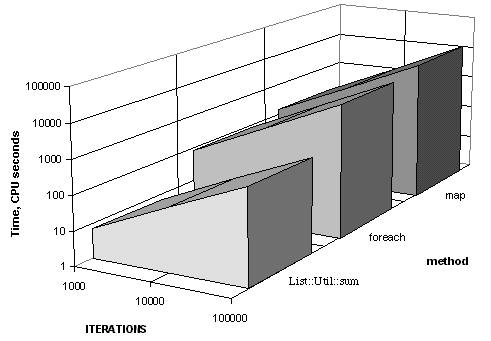
So what have I learned?
The stopwatch approach is not very effective for timing a piece of code because the CPU can work on other things before it finishes the one I want to time. The Perl builtin times is a little better, but my code might run faster than times can measure. I do not have to worry about these issues when I use the Benchmark module, which can average the time to run bits of code over many iterations and even compare different bits of code.
In my summing example, I discovered that the clever use of map() was consistently slower than the idiomatic foreach(), which was much slower than sum(). Although foreach() would be the idiomatic way to sum an array, I am hard-pressed to explain why absorbing an order of magnitude speed penalty is good—I will be using sum(). If you think that you have a faster method, you now have the tools to test it. If your method beats sum(), send me a note!
I did not show all of the things that you can do with the Benchmark module. Since I first published this article, another set of functions appeared. You can turn some of these benchmarks inside out by measuring the number of iterations that the computer completes in a set time which makes life much more satisfying when benchmarks seemingly do not quit.
References
- “Benchmarking Perl”, by brian d foy, The Perl Journal 11
Find the following modules on the Comprehensive Perl Archive Network (CPAN).
Some interesting links
I come up with these links much later, but still think they are interesting: