Jekyll2024-03-01T02:48:46+00:00http://briandfoy.github.io/feed.xmlbrian d foyRandom AdventuresBackups and resiliency for open source code2023-07-18T00:00:00+00:002023-07-18T00:00:00+00:00http://briandfoy.github.io/backups-and-resiliency-for-codeThe 3-2-1 rule is the basic advice about backups: have three copies, on two different types of media, in at least one far away location. That’s a good start, but there are other things to consider.
In this post I’m mostly thinking about my open source code. There are various laws and regulations that may control what you can do based on the type of data you have. For example, HIPPA or GDPR. I’m not writing about anything that secures or protects data, and probably writing things that do the opposite.
I already use several git services at once. I push to several different places so I have multiple copies and at least one far away location. I solve the two different sorts of media with various SSDs, HDDs, and the magical fairy dust of “internet”.
Pushing things to multiple git services, such as GitHub, GitLab, and Bitbucket, protects me from outages or adverse action at any of them. If GitHub is down, I still have access to my local copies, but also the copies on other services if I don’t have a local copy.
That’s a good enhancement to 3-2-1, but then I started thinking about where these services actually store my data. For example, if everything is just AWS us-east, then I might not have any sources available for a single AWS outage.
I looked at what I had and where it might be and what it might be using. Sometimes the technical details leak out where the business side would not be so open. I can’t verify these, so if I’m wrong, correct me:
GitHub - Rackspace? Azure? (Virginia, Seattle)
GitLab - Google Cloud Project, us-east (South Carolina, Virginia)
BitBucket - AWS us-east (Virgina)
Linode - Philadelphia or Southern New Jersey area (Akamai)
Pair Networks - Pittsburgh, or maybe the US midwest?
Suppose a hurricane takes out Virginia; how many of those services stored my data in the same building? In the same row of racks? In the same cabinet? I’m not surprised that most of these are coy about where my data actually live. I suppose I could ask them, but I don’t want to kick the bee hives.
For me, those are all hosted in the United States, and mostly in the same hurricane-prone area. The weather could be a big threat. I want at least one data store to be in a different weather regime.
Suppose that there is some adverse regulatory action that denies me access to my US accounts. I have been locked out of Gmail for a couple of weeks with no warning and no later explanation, for example. Maybe that was a glitch, but maybe I got caught up in some sort of weird government action, accidentally or otherwise. Consider GitHub and Trade Controls, where GitHub prevailed, but “[a]s a result of our advocacy and hard work with U.S. regulators”. I don’t believe if you are doing nothing wrong you have nothing to worry about, and neither should you if the mitigation and resiliency is easy.
Politics
Along with that, sets of politics have entered the chat. What if my account is shut down because I use the default branch “master” instead of some other branch? No one has gone that far, and I don’t really care, and the argument is not about “master”. There are political reasons that a service may suddenly deny me service because I either ignore their instructions to change something or I am blindsided by something I had no chance to respond to. The US business culture seemed to be moving toward a cancel first and ask questions later.
I don’t really care about “master” beyond the fact that all the tools are set up to look for it. I’d have to change quite a bit in my workflow to recognize a new name because it would still have to support the old default name for existing copies. You’ve probably experienced the chained nuclear reaction knock-on effects of seemingly trivial changes. It’s not simply using a new name.
Corporate transfers
While researching this, I realized that SourceForge is still a thing. I used to host everything there because SVN was the new hotness. Then they were acquired, got really weird, and everyone left. Some people complained that SourceForge became a clickbaity malware hosts, and I certainly noticed that they obfuscated what you were supposedly downloading. I’ll never trust them again, even though they changed hands again in 2016.
Some people were worried about the same thing when Microsoft acquired GitHub. I think they were unfounded as people have inculcated reactions based on the evil days of Bill Gates and Steve Balmer. Now we are in the days of Satya Nadella, who isn’t laying awake at night trying to destroy Steve Jobs or IBM. He seems like the adult in the room. GitHub has become flakier, maybe because it’s on Azure, but I think that would have happened because of scale in any situation.
But know this: everything that you love will eventually be sold and will eventually abandon the thing you loved about them. Google used to “Do no evil”, and is probably considered to be evil now. Travis CI said free open source “forever”, until they sold out. Consider that volunteer projects eventually scale to the point where they can’t be volunteer, hobbyist endeavors anymore. Consider that the hot shot engineers who made your cool service will eventually have children and their entire relationship to the world will change. People with families will absolutely take the big bucks from an acquisition over supporting your use case for eternity for free. Plan on it.
Bus factor
Additionally, the point of open source is that people should have access to my work product even without me. Maybe I’m on vacation, or maybe I’m in a coma in the hosptial (a true story from my first company, but with a different founder). It’s not merely my own access to my materials, but the world’s access. Suppose sanctions are applied against my country by some other country—part of the world might not be able to access my code (see where GitHub isn’t available by US law). Some single action could obviate everything I’ve done, so far, to keep my stuff available.
What else is out there?
I started to look around at what else there might be.
Create new repos with an API call
free for open source projects
lets me host several hundred repos
I don’t find much that’s suitable:
Codeberg.org is a gitea installation hosted by a volunteer group in Berlin. It has an API and is outside the US and outside the US jurisdiction. Germany is a US ally though, so if the US was really mad at me, I could still be bitten.
The granddaddy of all services, https://repo.or.cz, which has mirror mode. There’s no API, but the website is so simple I could probably wrap it very easily.
Where does that leave me?
I guess I’m mostly hosting in the Virginia.
]]>Encrypting secrets for GitHub’s API with Perl and libsodium2023-04-05T00:00:00+00:002023-04-05T00:00:00+00:00http://briandfoy.github.io/encrypting-secrets-for-github-s-api-with-perl-and-libsodiumThe GitHub API for
Secrets uses
libsodium to exchange the secret. I
request the public key for my repository, I encrypt my secret with my
repository’s public key, and I send it back to GitHub. My repository
can then decode it with its secret key (which I don’t know).
The API docs have examples in Node, Python, Ruby, and C#. I worked out
an example in Perl which takes the Base64 encoded public key as
provided by the API and returns the Base64 encoded secret I need to
send back.
sub _nacl_encrypt($plain, $public_key_base64) {state$rc=requireSodium::FFI;my$key_bin=Sodium::FFI::sodium_base642bin($public_key_base64);my$crypted=Sodium::FFI::crypto_box_seal($plain,$key_bin);returnSodium::FFI::sodium_bin2base64($crypted);}
While testing this, I wanted a way to look at the secret in GitHub Actions
so I knew that I had uploaded what I intended. However, GitHub masks
anything it thinks is a secret by replacing the secret’s text with ***.
Inside the action, I output the secret’s text with spaces between every
character:
jobs:update-ranges:runs-on:ubuntu-lateststeps:-uses:actions/checkout@v3-name:Show secretrun:|echo $ | sed 's/./& /g'
As an aside, it’s pretty easy to discover secrets this way. I simply
output enough text until I find text that GitHub Actions decides it should
mask. For things like personal access tokens, that’s a lot of combinations.
But for other things,
]]>The new Perl community on Twitter2023-01-20T00:00:00+00:002023-01-20T00:00:00+00:00http://briandfoy.github.io/the-new-perl-community-on-twitterI’ve made a new “Perl on Twitter” community because we’re trying to pass admin responsibilities and having no luck with that.
Remove yourself from the previous community. Mark needs to remove all members to leave himself.
At Mark’s convenience, the community he set up will eject all members and be shut down to the extent he can do that.
And, I have these settings:
Only members can post.
I’ve restricted membership, but members can invite people.
Why is this so hard?
Awhile ago, in the pre-takeover days, Mark Gardner set up a “Perl” community on Twitter. A bunch of people joined.
Then there was the corporate drama about Twitter and some people, including Mark, decided they wanted to go their own way. No problem—you do what you think you need to do. No judgment here.
I volunteered to take Mark’s place, but we couldn’t figure out how to transfer admin. We couldn’t figure it out like all the other people who’ve asked this question since the start of Twitter Communities. Not only that, Mark can’t leave the community because he’s the only admin. And, he can’t right out delete the community because it has members.
This really looks like a half feature to Twitter even prior to the Turmoil. Just like all the other poorly-designed social network things that were designed in a half-hour meeting and never given another thought.
For what it’s worth, I met some the Google Circle people at one of its launch parties and asked them about various failure patterns. It took them millions of dollars and years of effort to figure out what I casually told them. But hey, that’s software engineering, amirite?
As such, I figured it’s best to start over with a new community that I set up.
]]>A format for RPSL2023-01-18T00:00:00+00:002023-01-18T00:00:00+00:00http://briandfoy.github.io/a-format-for-rpslThe Routing Policy Specification Language is a pain in the ass, but at least it’s not XML. A RPSL object is a bunch of key-value pairs, with possible multiline values and comments (for example, RIPE’s files). Here’s a simple example for format (but not validity):
route: 1.2.3.4/32
origin: AS64512
admin-c: FOO
tech-c: FOO
remarks: This is the first line
This is a continuation line
This is another remark line
source: SomeIRR
The first thorn is the colon after the field name. Your first thought might be like mine: a printf with two format specifiers:
printf"%s: %s\n",$field,$value;
This simple format loses the column alignment, and doesn’t add the beginning whitespace RPSL needs for the continuation lines:
route: 1.2.3.4/32
origin: AS64512
admin-c: FOO
tech-c: FOO
remarks: This is the first line
This is a continuation line
This is another remark line
source: SomeIRR
Just make the field format a fixed width to get that alignment:
printf"%-12s: %s\n",$field,$value;
The field names are shorter than the field width so the placeholder is padded, which moves the colon away from the shorter names:
route : 1.2.3.4/32
I fixed this by moving the colon from the template to the value so it would be at the end of the field name and
printf"%-13s %s\n","$field:",$value;
With a little tortured logic, I can get this same template to work for continuation lines too since the first placeholder can be empty.
How about formats?
Sometimes we follow these paths further than we should and don’t consider other alternatives. A co-worker half-jokingly suggested Perl’s formats might work, but neither of us followed up on that because we weren’t going to do that in production anyway. Still, the task gnawed at me and I had to give it a try just so I could stop thinking about it. Here’s a RPSL formatter using format:
usev5.36;usevarsqw($k $v);formatRPSL=^<<<<<<<<<<< ^*
$k, $v
~~ ^*
$v
.
my%hash=(_class_key=>'route',# this key needs to be firstroute=>'1.2.3.4/12',origin=>'AS237',remarks=>"first line\nsecond line\nthird line\n",address=>"1234 Main St\nAnytown, MI 12345",'admin-c'=>'MAINT-AS237',);# just do the first line, which is the class keymy$field=delete$hash{_class_key};do_field($field,delete$hash{$field});# the rest of the fieldsforeachmy$key(keys%hash){do_field($key,$hash{$key});}# Add the rest of the fieldssub do_field( $field, $value ) {my$old_handle=select(STDOUT);local$~="RPSL";# name of format to use for current filehandlelocal$k="$field:";local$v=$value;writeSTDOUT;select$old_handle;}
This gets me the nicely formatted object where the multiline address and remarks value are nicely aligned:
route: 1.2.3.4/12
address: 1234 Main St
Anytown, MI 12345
origin: AS237
admin-c: MAINT-AS237
remarks: first line
second line
third line
Since this is a pre-v5 feature, it doesn’t work with the things that Perl 5 gave us: lexical filehandles and variables. I have to work with the Perl 4 bareword filehandles and package variables.
Perl’s format has some implicit knobs and dials, and most of them are at least distasteful in today’s world. When I call write STDOUT, it looks for a format of the same name as the bareword filehandle. Or, more correctly, it looks in the $~ per-filehandle variable that specifies the format name, which is the same as the filehandle name by default. Since I’ve named my format RPSL, I have to set the per-filehandle variable $~ to the name of the format I want to use. To do that properly, I need to first select the filehandle I want in case it’s not currently the default, change the value of $~ to the one I want, and at the end, reselect the previous default filehandle to undo my mess. I can’t do this just once because someone else may have changed the defaults for their own purposes. It’s essentially global variable hell.
I also have to set the package variables $k and $v since those are the package variables I use in the format. It’s the global variable problem again, so I liberally use local to restore their previous values at the end of the scope.
Sure, it’s ugly, but I’ve also compartmentalized it in the do_field subroutine. I’ll come back to that in a moment because I’m still in the land of formats. Just know that all the ugliness is in one place.
The template itself isn’t that tricky, although I did read through the original formats chapter from the first edition of Learning Perl and check the perlform docs. I used to use formats a lot (mostly for paginated output I’d have to print on dead trees), but I haven’t touched them for years. I knew what I wanted to do and that formats could do it, but I’d forgotten it’s tricky syntax.
Here’s just the format again:
formatRPSL=^<<<<<<<<<<< ^*
$k, $v
~~ ^*
$v
.
The basic setup is easy. There’s the first format line that specifies the name, and the . line that ends it. Between those two lines are couplets of a template line and a variables line.
The first template line is simple: there’s a fixed-width field and a variable width field. No big whoop. At least, it’s no big whoop until $v has multiple lines (so, embedded newlines). The first template line only formats that first embedded line in $v and defers on the rest of the lines in $v.
It’s the second couplet that is the one that makes format an interesting feature for RPSL objects. The ~~, line tells the format to only use this part of the template as long as there are data the variables that it hasn’t yet formatted; this handles the continuation lines in the RPSL values. If Perl has completely used up the value in $v, it doesn’t process the ~~ line. Otherwise, it takes the next line from $v and uses that to fill in the template. After it fills in this template, it looks at $v again to see if it still has data to format, and if so, the ~~ does its work again. It keeps doing this until $v is exhausted.
The only ugly thing about that is the bareword filehandles. And the per-filehandle settings. The two things that are ugly are the bareword filehandles, per-filehandle settings, and the global variables. I did have to know the format, including the field width ahead of time, but that’s not such a big deal.
Perl6::Form
Generally I try to use built-in features if I can get them to work, but there are various modules, such as Perl6::Form, that get away from the built-in format problems. Here’s do_field reimplemented for that (with no other code changes):
sub do_field( $field, $value ) {state$rc=requirePerl6::Form;printform{layout=>"tabular"},'{[[[[[[[[[[} {[[[[[[[[[[}',"$field:",$value;}
That’s certainly simpler in the code I typed out, but it also requires another dependency to get to the same place I was before. How much that matters is a personal decision though.
I basically lifted that example out of the Perl6::Form docs and it worked. But, that module has its own problems. Damian Conway solves tricky problems in amazing ways that cover lots of cases, but those amazing ways have their own knobs and dials. This example came from the multiline section that noted that I needed to set the layout type to get it to work correctly.
]]>Speeding up my secrets2022-12-16T00:00:00+00:002022-12-16T00:00:00+00:00http://briandfoy.github.io/speeding-up-my-secretsIn Putting environment values in the keychain, I showed how I use the macOS keychain to store passwords and then read those into my shell’s environment. It worked, but it’s also a bit annoying; every time I start a new interactive shell, I have to wait five seconds for it all to happen. Now I’ve fixed that.
The problem was that every time I started the shell I made many calls to the bash function get_secret:
This means that I’m likely fetching the same data over and over even though it hasn’t changed. These values are often API keys, constants, and other things that probably haven’t changed in months. Still, I reload them several times an hour as I open new terminals.
I decided that I’d precompute everything I need and have it ready to go. That’s easy enough. I basically do what I was doing before, but I write everything to a file that will stick around. My .bash_profile then sources this text:
# ~/.bash_secrets_base_gpgsource ~/.get_secret.sh
s=''# Appveyors="${s}export APPVEYOR_API_KEY=$(get_secret appveyor_api_key)\n"# For Amazon Web Servicess="${s}export AWS_ACCESS_KEY=$(get_secret aws_access_key)\n"s="${s}export AWS_SECRET_KEY=$(get_secret aws_secret_key)\n"s="${s}export AMAZON_ASSOCIATES_TAG=$(get_secret amazon_associates_tag)\n"s="${s}export DBD_AMZN_USER=$(get_secret dbd_amzn_user)\n"echo-e"$s"> .bash_secrets # this line will disappear
What’s the point of the secrets store if it’s just sitting there as text? Now comes the fun part. I’ll encrypt that string with GPG and save that. I store the destination file and target key in the secrets too, but mostly as a coordination point for all the scripts that might use this. GPG gets its plaintext directly from standard input:
# still in ~/.bash_secrets_base_gpggpg_fingerprint="$(get_secret bash_secrets_gpg_fingerprint)"output_file="$(get_secret bash_secrets_gpg_filename)"echo-e$s | gpg --encrypt--armor-r$gpg_fingerprint>$output_file
On the other side, in .bash_profile, I go backward. There’s a nested if here. I don’t want to run this if I’m running a program through BBEdit. No big whoop:
The inner if is where the magic happens. I use find to compare the file modification time against what I put in day. The --mtime -1 fails if the file is over a day old. In that case, I want to regenerate the secrets file.
Once I have the secrets file, either reusing a fresh one or recreating it, I decrypt that in place. The password comes in from the keychain too and gets to gpg through standard input. The gpg output ends up in plain without touching the disk.
With the plaintext in a variable, I source that string. This little trick requires bash 4 on macOS because bash 3 had a bug that prevented this feature from working.
]]>I hold my pen differently2022-11-03T00:00:00+00:002022-11-03T00:00:00+00:00http://briandfoy.github.io/i-hold-my-pen-differentlyWhen I write, I hold my pen between my index and middle fingers, and until today, I’ve only encountered two other people who do that. One was a waitress, which is an important detail for this story.
I might have started doing this very early in college, but I would rule out starting at the end of high school. So, lets say that’s 1990. This is also important because that was 32 years ago, and Taylor Swift is 33.
The 1990s were pre-laptop days, so people (students) did a lot of writing. I’d aggressively hold my pen and end up with sore and cramped fingers. So, I changed. The pen between the index and middle fingers basically stays in place by the natural tendency of the fingers to stay together.
If I stop writing, I can actually fold the pen into my palm and leave it there while still having use of my hand. This is likely why the waitress also did it: she didn’t have to give up the use of one hand because she was holding a pen.
Now I learn that Taylor Swift holds her pen like that, and the internet has been losing their minds over it. There’s a Quora question. There’s a [reddit thread of a preschool teacher clutching her pearls and yelling “Think of the children”]. One of the richest and most successful musical artists, the one who tells Spotify what to do and they do it, is wrong? Some broke-ass wage slave in Ohio thinks they have the answer?
The surprising bit is that my handwriting didn’t change and there was almost no adjustment period. I was able to write normally with the same penmanship I had before.
Here’s Taylor writing in the video.
And here’s her doing it 10 years ago in a Diet Coke ad
I’m pretty sure I’ve never met Taylor Swift and even if I have, she didn’t see me writing anything. Still, I’ve been doing this about as long as she’s been alive.
how can you not break yourself of your serial killer tendencies and learn how to hold a pen properly?
Kylee then goes on to rant about children, which, despite her fanbase of 13-year girls, is not a child. Kylee’s screed completely misses the point. These complaining people see Taylor Swift as a pre-teen sex object who was mistakenly allowed to make a decision on how she does something that affects no one else.
Why we do things the way we do
As children, we do things a certain way because we have small hands and poor motor control. We don’t have to keep doing things designed for small hands with poor motor control when we have big hands and good motor control. She almost makes this point because she notes that kids progress from the caveman death drip with utensils and crayons to the conventional “tripod” grip most people use with a pen.
Now consider tying our shoes. Most of you are doing it wrong because the rabbit ears method you were taught makes an uneven knot. You were taught that because you did not yet have the finger dexterity to do something better. Small hands simply can’t manipulate the laces well enough to make the Ian Knot:
Notice in this knot, the loops of the knot lay across the foot (perpendicular to the long axis of the foot). That know has equal tension throughout. If your loops don’t do that, you are doing it wrong. Which is why kids, and many adults, have to keep tying their shoes when the improper knot comes loose.
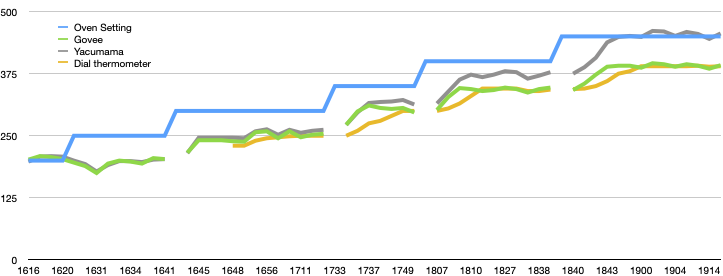
]]>Calibrating my oven2022-08-22T00:00:00+00:002022-08-22T00:00:00+00:00http://briandfoy.github.io/calibrating-my-ovenAfter a baking disaster, I decided to calibrate my oven. When the dial says 375, what is the actual temperature? This oven is a fairly new, so I don’t have a feeling about what it’s doing like I had with the previous one. I suspect this oven is about 50 F too low.
The setup
I have a cheap dial thermometer from Taylor which I keep in the oven. I figure that’s not very accurate, but I did specifically buy it based on its brand.
I mostly use a Govee grill meat thermometer, which I like for its simplicity. I turn it on and it tells I the temp.
On the first go I just hung the probes from the oven rack, but the results were weird. one of the probes had shifted to touch the rack below and the side of the oven.
I constructed a holder from some spare silicon to hold the probes away from everything.
None of these have been calibrated at high temps. I don’t even know how I’d do that; would I use boiling glycerin (554 F)? Now I wonder if my rangetop could boil glycerin. I don’t think I’ve even done that in a working wet lab.
And, as always, remember what my Analytical Chemistry professor told our class: these thermometers were bought from the lowest bidder. As part of that, we usually had at least thermometers involved in any experiment.
The results
I think I’m right. My oven dial is 50 F off. The Govee and the Taylor largely agree. The Taylor takes a long time to respond, but once it does, it’s steady.
The Yacumama agrees with the other two until it doesn’t. That doesn’t make it a bad thermometer. As a meat thermometer, it really needs to be accurate to about 175 F. After that most people don’t care.
My oven’s maximum temp is about 400 F. This is a problem for some bread recipes which want 500 F at the beginning and 450 after that.
I haven’t bothered to adjust the temperature knob to realign it. Maybe that’s a solution.
]]>A CPAN distroprefs example2022-06-29T00:00:00+00:002022-06-29T00:00:00+00:00http://briandfoy.github.io/a-cpan-distroprefs-exampleThe Data::Match module has some syntax that Perl v5.22 tightened up. That’s why it fails. Note that force installing a module with an egregious problem like that means it will just fail when you run your program.
If you can, don’t use this module. I have no idea what it does, so I don’t have any suggestions for a replacement.
Let’s suppose you need this module for whatever reason, even though it’s 20 years old. Perhaps you’re supporting a legacy app that you just need to get working.
There’s this line (L968) which dereferences an array element that is itself an array reference:
$str .= $sep . '{' . join(',', @$ind->[0]) . '}';
That should be the circumfix notation to delimit the reference part:
If you make that change to Match.pm before you run perl Makefile.PL, the tests pass (but with a warning) and you can install the module.
If that’s all you need, you can stop here.
Distroprefs
CPAN.pm has a way to handle these situations so you don’t have to make the change every time you want to install the module. Before CPAN.pm does its work, it can patch the problem distribution, suggest a replacement distro, or many other things. You do this with “distroprefs”. There are many examples in the CPAN.pm repo.
There are a few things to set up. First, choose your distroprefs directory (o conf init prefs_dir). Second, configure a directory to hold your patches (o conf patches_dir). I choose patches under my .cpan directory, but it can be anything. Save your changes before you exit.
% cpan
% cpan[1]> o conf init prefs_dir
Directory where to store default options/environment/dialogs for
building modules that need some customization? [/Users/brian/.cpan/prefs]
% cpan[2]> o conf patches_dir /Users/brian/.cpan/patches
% cpan[3]> o conf commit
distroprefs has two parts. The first specifies what you want to happen. This can be a YAML, Storable, or Data::Dumper file. If YAML (which most people seem to use), then you need to install the YAML module first.
Here’s a simple distroprefs file. It tells CPAN.pm how to match a distribution as you’d see it on CPAN (AUTHOR/FILE). In this example, its action is patches, which is an array of patch files. Since you set up patches_dir, that’s where it will look. The file name for the patch isn’t special, and it can be compressed. I chose the distro name, my name as the person who patched it, then .patch.
Now when you try to install Data::Match with cpan, it knows that it’s installing Data-Match-0.06, it matches that distro from a distroprefs file, and that distroprefs file tell CPAN.pm to perform an action. In this case, it needs to find the patch file and apply it. After the patch is applied, the tests pass and the installation succeeds:
% cpan Data::Match
Reading '/Users/brian/.cpan/Metadata'
Database was generated on Wed, 29 Jun 2022 05:56:00 GMT
Running install for module 'Data::Match'
______________________ D i s t r o P r e f s ______________________
Data-Match-0.06-BDFOY-01.yml[0]
Checksum for /Users/brian/.cpan/sources/authors/id/K/KS/KSTEPHENS/Data-Match-0.06.tar.gz ok
Applying 1 patch:
/Users/brian/.cpan/patches/Data-Match-0.06-BDFOY-01.patch
/usr/bin/patch -N --fuzz=3 -p0
patching file Match.pm
Configuring K/KS/KSTEPHENS/Data-Match-0.06.tar.gz with Makefile.PL
Checking if your kit is complete...
Looks good
Generating a Unix-style Makefile
Writing Makefile for Data::Match
Writing MYMETA.yml and MYMETA.json
KSTEPHENS/Data-Match-0.06.tar.gz
/usr/local/perls/perl-5.36.0/bin/perl Makefile.PL -- OK
Running make for K/KS/KSTEPHENS/Data-Match-0.06.tar.gz
cp Match.pm blib/lib/Data/Match.pm
cp lib/Sort/Topological.pm blib/lib/Sort/Topological.pm
Manifying 2 pod documents
KSTEPHENS/Data-Match-0.06.tar.gz
/usr/bin/make -- OK
Running make test for KSTEPHENS/Data-Match-0.06.tar.gz
PERL_DL_NONLAZY=1 "/usr/local/perls/perl-5.36.0/bin/perl" "-Iblib/lib" "-Iblib/arch" test.pl
1..1
# Running under perl version 5.036000 for darwin
# Current time local: Wed Jun 29 15:54:13 2022
# Current time GMT: Wed Jun 29 19:54:13 2022
# Using Test.pm version 1.31
ok 1
PERL_DL_NONLAZY=1 "/usr/local/perls/perl-5.36.0/bin/perl" "-MExtUtils::Command::MM" "-MTest::Harness" "-e" "undef *Test::Harness::Switches; test_harness(0, 'blib/lib', 'blib/arch')" t/*.t
t/t1.t .. ok
t/t2.t .. ok
t/t3.t .. 1/15 splice() offset past end of array at /Users/brian/.cpan/build/Data-Match-0.06-15/blib/lib/Data/Match.pm line 1941.
t/t3.t .. ok
t/t4.t .. ok
All tests successful.
Files=4, Tests=182, 0 wallclock secs ( 0.03 usr 0.01 sys + 0.18 cusr 0.04 csys = 0.26 CPU)
Result: PASS
]]>Another reduction example2022-06-29T00:00:00+00:002022-06-29T00:00:00+00:00http://briandfoy.github.io/another-reduction-exampleI started to answer a StackOverflow question, but it was deleted before I could get back to it. The person was trying to figure out what an if branch was doing.
Often, programming, well, good programming, relies on our ability to reduce problems to known solutions. This relies on our ability to see structures and patterns, and possibly see possible structures.
The Answer
Here’s your code, indented so I can see what belongs to what:
The outer if checks some variable for the run mode, then does the same operation with a slightly different regex. Here are the patterns aligned so that you see that the second pattern has QA/ at the front:
The problem is that the structure hides that simple difference. The if is only there to select between slight differences before going on to do the same thing.
One way to fix that is the take the pattern out of the loop. You can use the qr to build a regex without using it, and you can even use that result inside another regex to make a bigger one. Once you have the final pattern, apply it with m// as usual:
Another tactic reduces the problem so you can use the same pattern. If you remove QA/ from the start of the string in some cases, then you don’t need to modify the pattern.
I use Finder labels, also know as “tags”, to organize the files in directories. Suppose that I have a bunch of data files to inspect. I’ll mark the really interesting ones as Red, the ones I’ve seen as Orange, and the ones I can ignore as Yellow.
But, the interface for this is annoying. Select a file, right-click, select a color, and repeat. There has to be a better way.
I had been looking for an excuse to try Hammerspoon, a Lua-based macOS interface controller. I can bind keys to actions and I can tag files. The thing it apparently can’t do easily is access the list of files selected in a Finder window. If I’ve missed how to do that, let me know by pointing at some docs.
You may ask about AppleScript at this point. That’s possible, probably, activating it is just slow enough that it’s painful. Hammerspoon did its work quickly with no perceptible lag.
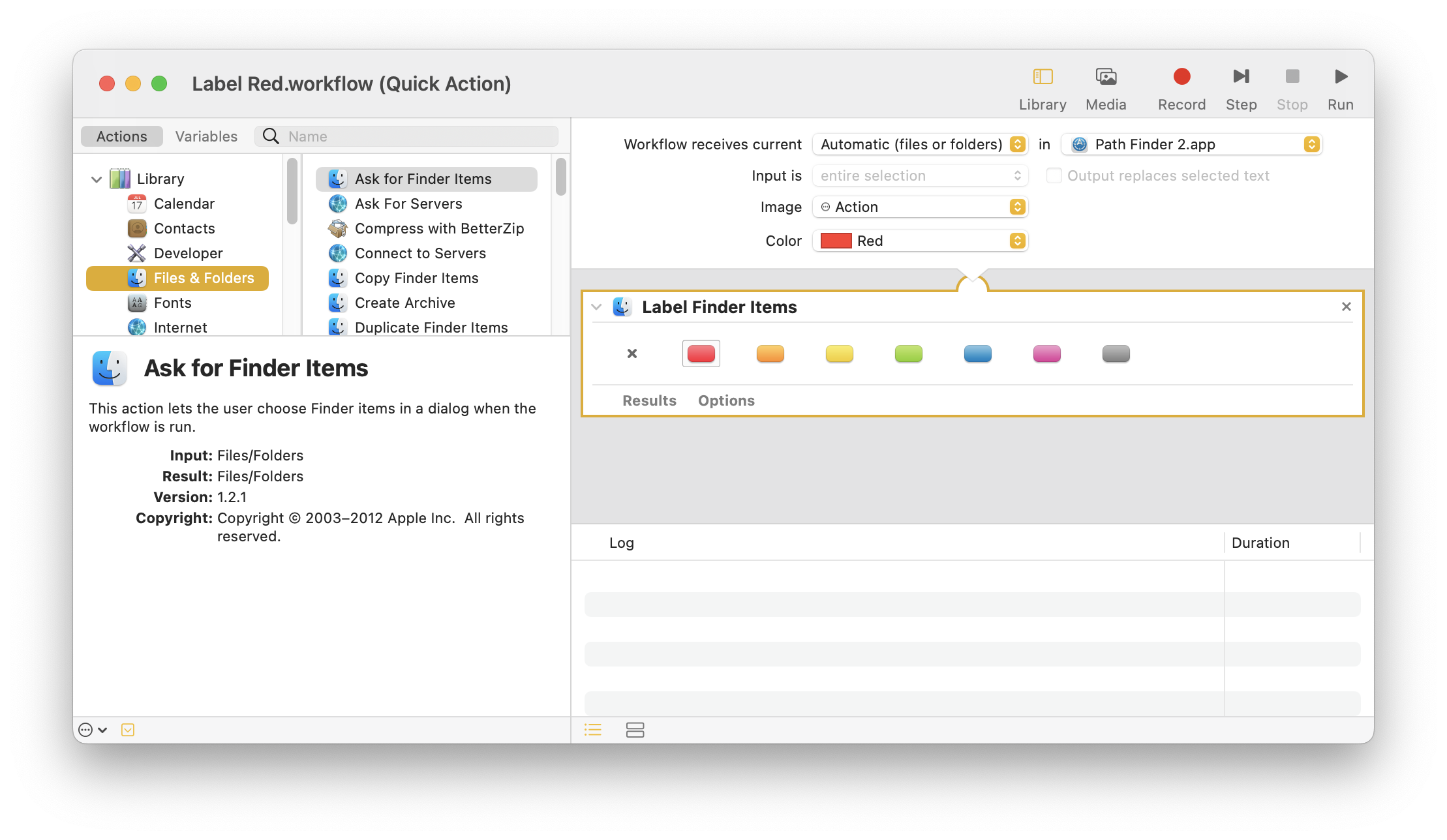
Then I had the idea to use Automator, which I haven’t really enjoyed using in the past. I created a Quick Action to label an item. That looks deceptively simple:
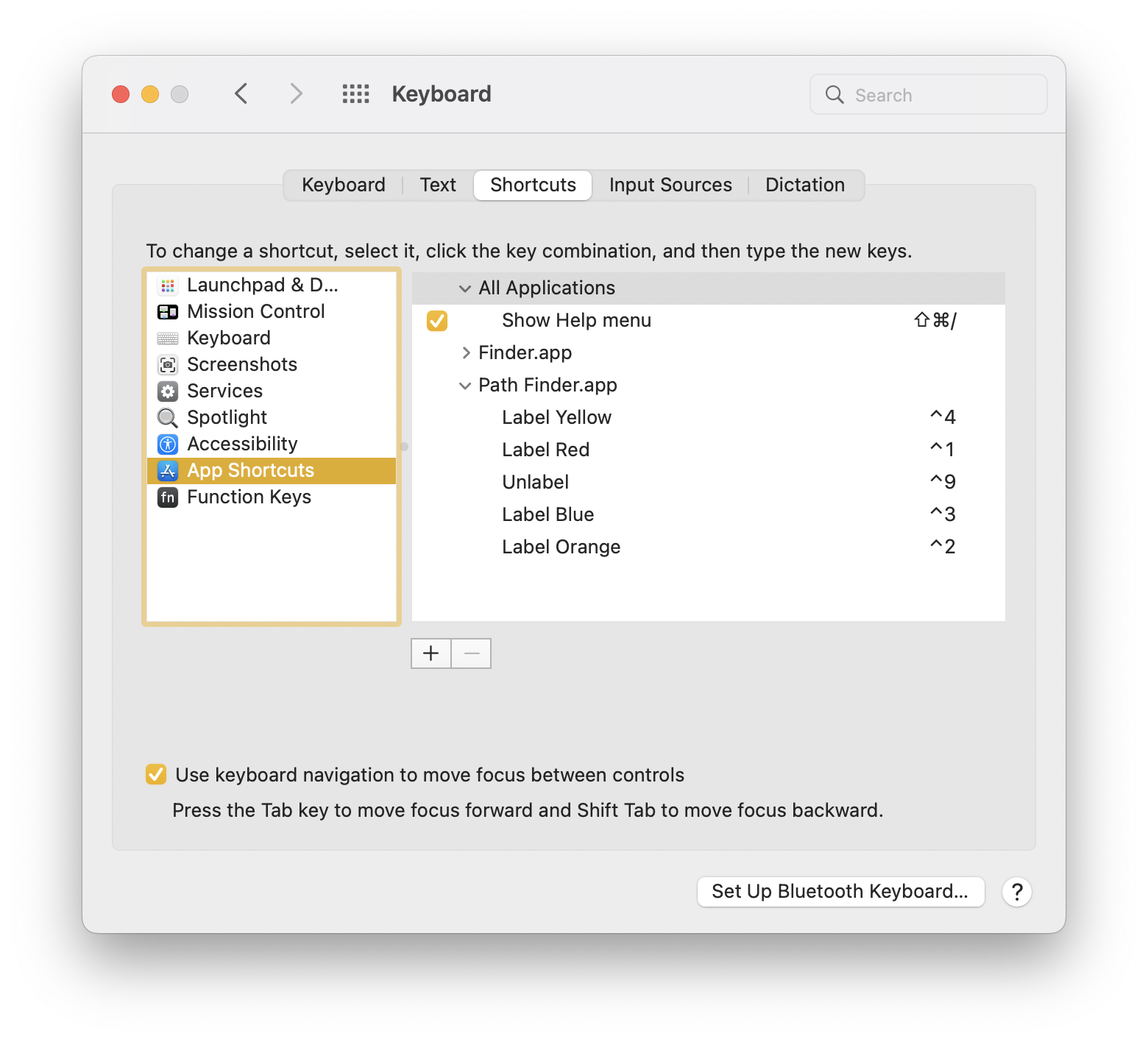
I then bound that Quick Action to a key combo in System Preferences > Keyboard > Shortcuts > App Shortcuts. I chose Control-digit because it uses one modifier key:
Now here’s the problem: I don’t have an action to add a new tag. I have an action to unset all existing tags and set a new one. And, Automator doesn’t provide a sufficient interface to get the set of existing tags for an individual file, add one to that list, then set all of those.
I can label an item with exactly the label the service specifies, unsetting all the other labels. This is the problem I’ve run into Automator in general. Notice that Automator calls these “Labels”—that’s old school. Mavericks turned labels into tags, making it possible to not only define your own tags but to add more than one tag to a file. It’s quite annoying because these tags show up as little dots instead of highlighting the entire line.
But, you’ll also notice that I’ve bound the keys to Path Finder.
While testing, I somehow ended up in a Finder window. I tried my new shortcuts in Finder, and it worked like I thought it would. Then I tried another shortcut to change the tag, and that worked. But, this time, it didn’t unset the tag that I had just set.
Wait, what? I thought I had set these shortcuts in Path Finder. Why are they showing up in Finder? Well, they were already there. Not only that, but they toggle a single tag without affecting others.
I went through a lot of work to discover that Finder already does what I want. It’s hidden in an Apple Support doc and not shown in the contextual menu.
Ctrl1 - Red
Ctrl2 - Orange
Ctrl3 - Yellow
Ctrl4 - Green
Ctrl5 - Blue
Ctrl6 - Purple
Ctrl7 - Grey
Ctrl0 - Clear all
So damn, I get what I want, in the way I reinvented it